Training In Supply Chain Analytics: Charlotte NC, January 30 2024
Hello Charlotte, NC supply chain professionals! On the heels of August’s training in Minneapolis, “Supply Chain Analytics in R”, Jeff Clement, PhD and I are taking the show the road to Charlotte: Tuesday, January 30, 2024. This training will include: – Types of supply chain data– Types of charts and graphs and when to use […]
Free tools for spatial data visualization in R and Python
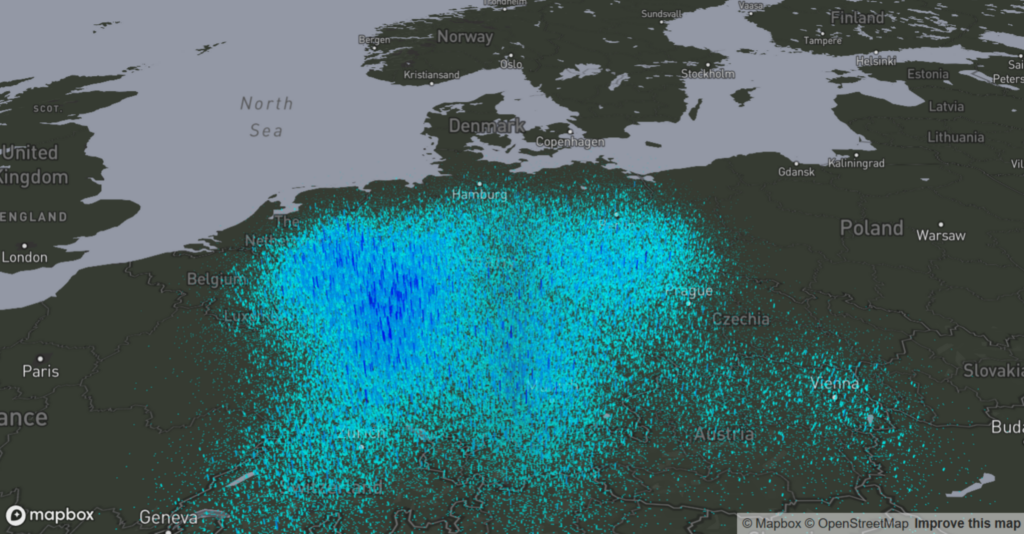
This is a guest post by Linnart Felkl, of supplychaindataanalytics.com Supply chain network design can benefit greatly from spatial data visualization. For example, transparency in a warehouse relocation project can be greatly improved by visualizing material flows and critical transportation routes as well as e.g. spatial customer location distribution. In this blog post I present […]
Why Is Everybody Parking Near My Car? And Other Adventures in Discrete-Event Simulation
Note: This content is an introduction to simulation, a powerful tool for analyzing complex supply chain decisions. Simulation allows allows decision-makers to test scenarios, assess risk, and optimize systems without disrupting real operations. To be accessible to a wide audience, this content is not supply chain-specific. However, simulation can be used to improve supply chain applications […]